
4 EMPIRISCHE UMFRAGE
Dieses Kapitel widmet sich der Erstellung einer in drei Sprachen standardisierten empirischen Umfrage. Der erarbeitete Fragebogen soll systematisch überprüfen, inwieweit der Rezipient dazu in der Lage ist, Fake News zu erkennen. Dabei wird getestet, wie schwer es ist, unbekannte Fakten von Fiktion zu trennen. Des Weiteren soll die Meinung der Probanden über die Medien erfasst werden sowie das Verhalten, welches den Erfolg von Fake News unterstützt.
Da das Thema Fake News in der Öffentlichkeit breit diskutiert wird, es jedoch keine rudimentären Zahlen dazu gibt, wurde ein quantitatives Forschungsdesign gewählt, damit die Ergebnisse statistisch ausgewertet werden können. Das gewählte Design verspricht eine optimale Bearbeitung der Forschungsfrage mit einer Vielzahl möglicher Probanden. Da sich das Thema Fake News nicht auf einen nationalen Medienmarkt beschränkt, fiel die Entscheidung auf eine internationale Herangehensweise. Dazu wurde ein Onlinefragebogen in drei Sprachen erstellt (Deutsch, Englisch, Russisch). Die Übersetzung erfolgte mithilfe von Muttersprachlern oder Personen auf Muttersprachenniveau. Wie weit der Fragebogen in anderen Sprachen angenommen wird, hängt mit der Art der Verteilung des Bogens zusammen. Hierfür wurden die sozialen Medien und ihre Vielschichtigkeit genutzt, um eine möglichst breite unbekannte Masse anzusprechen.
Der Onlinefragebogen hat zudem den Vorteil, dass er die persönliche Beziehung zwischen Befragten und Fragenden aus der Gleichung nimmt. Die Beantwortung des Fragebogens kann jedoch nicht aktiv überwacht werden. Die Funktion des Wissenschaftlers wird allein auf die Funktion des Designens und die anschließende Auswertung beschränkt.
4.1 Forschungsdesign
Um zu beantworten, wie weit der normale Rezipient von Nachrichten dazu in der Lage ist, Fake News selbstständig zu erkennen, bietet sich ein einfacher experimenteller Niveautest an. Innerhalb eines Onlinefragebogens müssen die Probanden selbstständig erkennen, ob die Nachricht, die sie gerade lesen, echt ist oder es sich um eine Fälschung handelt. Dabei können sie sich nur für Richtig oder Falsch entscheiden. Für den Test werden keinerlei zeitliche Vorgaben gemacht. Die daraus gewonnenen Antworten können anschließend quantitativ ausgewertet werden. Die Beantwortung der Fragen erfolgt digital nach einem Multiple-Choice-Verfahren. Mögliche Antwortursachen können jedoch nicht mit dieser Art der Befragung untersucht werden.
Bei der Befragung wurden den Probanden keine Regeln vorgegeben. Sie wurden nur vorab darüber informiert, dass die Befragung im Durchschnitt nicht länger als drei Minuten dauern würde. Diese Dauer ist das Ergebnis des vorher durchgeführten Pretests. Nach der Pretestphase wurde der Fragebogen angepasst und erhielt anschließend seine letztendliche Form (Anhang 1: Umfrage).
Die Erstellung des Fragebogens erfolgte durch ein Tool namens „Google Forms®“. Dieses Tool garantiert eine einfache Bedienung bei der Erstellung und Beantwortung. Das Tool macht eine direkte Auswertung möglich. Es hat zudem große Auswahlmöglichkeiten für die Gestaltung der Umfrage (beispielsweise: Fragegestaltung und Layout).
Im ersten Teil der Befragung werden persönliche Angaben von den Probanden ermittelt. Die Benutzung des oben genannten Tools macht es möglich, alle Fragen als Pflichtfelder zu markieren. Dadurch kann der Proband bei der Bearbeitung keine Fragen überspringen. Dieser Zwang kann aber dazu führen, dass die Umfrage vorzeitig abgebrochen wird. Abgebrochene Antworten werden von Google Forms® nicht erfasst und können somit auch nicht ausgewertet werden.
Nach den persönlichen Angaben folgen die ersten Fragen. Diese klären ab, ob die Probanden mit der Thematik der „Fake News“ vertraut sind, wie ihr Bild über die Medien ist und ob sie denken, selbst erkennen zu können, was wahr und was falsch ist. Das Selbstbild der Probanden wird in der Regel von dem tatsächlichen Bild abweichen. Die verschiedenen Untersuchungsgruppen bilden sich durch die verschiedenen Sprachvariationen. Diese ermöglichen eine Untersuchung von Probanden, die unterschiedliche freie Medien in ihrem Alltag gewohnt sind. Die Umfrage kann so aufzeigen, welche Unterschiede bei der Beantwortung zu erkennen sind.
Der Hauptteil der Umfrage bildet ein Blog aus selbst erstellten Fake News (siehe Anhang 1: Umfrage). In diesem Blog müssen die Probanden selbstständig entscheiden, ob das Gelesene wahr oder unwahr ist. Zudem wurde eine dritte Auswahlmöglichkeit hinzugefügt. Mit „Fake, will ich aber trotzdem lesen“ können die getesteten Personen signalisieren, dass sie zwar wissen, dass es eine Lüge ist, sie sich aber trotzdem dafür interessieren. Damit kann später eine Aussage getroffen werden, inwieweit Fake News erkannt, aber trotzdem gelesen werden, beziehungsweise wie groß das Desinteresse gegenüber Fake News ist.
4.2 Datenerhebung und Datenaufbereitung
Die Stichprobenerhebung erfolgte online. Der Fragebogen wurde an verschiedenen Stellen in sozialen Medien geteilt. Diese Stellen sind geschlossene Gruppen mit mehreren Tausend Mitgliedern. Diese Teilöffentlichkeiten ermöglichen es, eine möglichst breite Masse anzusprechen, so ist ein Teil der Teilnehmer willkürlich ausgewählt. Dennoch ist es schwer unbekannte Personen zu einer Teilnahme an einer Umfrage zu bewegen. Es ist davon auszugehen, dass nur wenige aus solchen Teilöffentlichkeiten an der Umfrage ohne Anreiz teilnehmen. Auf das Angebot eines finanziellen Anreizes wurde aufgrund der im Rahmen einer Bachelorarbeit zur Verfügung stehenden Mittel abgesehen.
Um möglichst viele Antworten zu bekommen, wurden zudem persönliche Kontakte angesprochen. Aufgrund des zeitlichen Rahmens einer Bachelorarbeit wurde davon abgesehen, die Zielgruppe zu beschränken, um so eine große Anzahl von Personen für die Umfrage zu gewinnen. Ziel war eine Teilnehmergröße von mindestens 100 Personen.
Nach der Erhebung wurden die Daten ausgewertet. Dabei half das verwendete Tool. Es fasste gleiche Antworten zusammen und setzte diese prozentual ins Verhältnis. Des Weiteren konnten die Daten in eine Excel®-Datei umgewandelt werden und stehen für weitere Untersuchungen zur Verfügung. Dadurch kann nach möglichen Antwortmustern gesucht werden.
Die Daten sollten zudem deskriptiv aufbereitet werden. Durch den internationalen Ansatz der Umfrage in drei verschiedenen Sprachen können die Teilnehmer in verschiedene Populationen eingeteilt werden. Hierbei wird das Wort „Population“ biologisch verstanden. Der Begriff beschreibt alle Individuen einer Art, welche an einem Ort zusammenleben. Die Antworten stammen aus dem europäischen, dem russischen und dem arabischen Raum; somit ergaben sich drei Gruppen. Da alle der arabischsprachigen Teilnehmer in Europa leben, wurden diese der europäischen Population zu gerechnet. Dies gründet auch darauf, dass sie aktuell vermehrt europäischen Medien ausgesetzt sind. Nach der Bildung der Populationen wurden die Antworten nach Häufigkeiten und Anteilen untersucht. Zudem wurde die Umfrage stochastisch analysiert und anschließend visualisiert.
4.3 Datenauswertung
Die Datenauswertung erfolgte mithilfe des Computerprogramms „Microsoft Excel®“. Die Kategorisierung der Antworten wurde durch die Fragen vorgegeben. Die Populationen wurden einzeln und insgesamt analysiert. Bei der Auswertung wurden deskriptive Verfahren angewandt und so relative und absolute Häufigkeiten ermittelt. Da keine Fragen durch eine numerische Skale beantworten werden konnten, wurden für die Fragen keine Mittelwerte bestimmt.
Bei näherer Betrachtung der Zahlen des experimentellen Tests fiel auf, dass es keine stochastische Verteilung der Antworten gibt. Daraus ist zu schließen, dass die Antworten nicht zufällig ausgewählt wurden. Um zu bestimmen, ob die Fragen des Niveautests für die Probanden schwer zu beantworten waren, wurde ein Schwierigkeitsindex ermittelt.
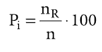
„Der Schwierigkeitsindex einer Aufgabe ist gleich dem prozentualen Anteil der auf diese Aufgabe entfallenden richtigen Antworten in Beziehung zur Analysestichprobe von der Größe n; der Schwierigkeitsindex liegt also bei schwierigen Aufgaben niedrig, bei leichten hoch.“
Lienert & Raatz (1998): „Testaufbau und Testanalyse“, Weinheim Basel – Seite 73
Ermittelt man den Schwierigkeitsindex, so kann man anhand des gewonnen Wertes ablesen, ob die Fragen schwer oder leicht zu beantworten waren. Dafür gibt es folgendes Schema:
Tabelle 1: Schwierigkeitsindex
| Wert des Schwierigkeitsindex | Frageniveau |
| 0 kleiner 20 20 bis 80 größer 80 100 | absolut schwer hoch mittel (optimal) niedrig absolut leicht |
4.4 Berichtlegung
Aufgrund der Anzahl der Teilnehmer – 166 – muss man von einer nichtrepräsentativen Umfrage sprechen. Alle durch die Stichprobe gewonnen Ergebnisse können sich mit einer größeren Anzahl von Teilnehmern noch ändern. Aus Gründen zeitlicher, finanzieller und organisatorischer Art konnte keine Vollerhebung durchgeführt werden. Alle gewonnenen Ergebnisse repräsentieren daher nur mögliche Ergebnistendenzen.
Da es das Ziel des experimentellen Tests war, die Probanden in die Irre zu führen, kann nicht belegt werden, wie sich die Teilnehmer der Untersuchung in der Realität beim Rezipieren von Medien verhalten. Es können nur Vermutungen angestellt werden, inwieweit eine Umfrage vergleichbar mit dem tatsächlichen Konsum von „Fake News“ ist. Teil der Untersuchung ist es nicht, bis zu welchen Grad die Umfrageteilnehmer die durch die Umfrage verbreiteten Fake News weitergeben. Unklar ist auch, wie weit sie überprüfen, ob das Gelesene die Wahrheit ist oder nicht. Das Verhalten der Probanden während des Tests wurde nicht untersucht, sondern nur einzeln hinsichtlich eines bestimmten Aspektes abgefragt. Dieser Aspekt war, inwieweit die Probanden mithilfe einer Suchmaschine überprüft haben, ob die gelesene Nachricht der Wahrheit entspricht. Kein befragter Proband tat dies, da er/sie entweder den Gedanken nicht hatte oder der Meinung war, dass es die Umfrage verfälschen würde.
Bei der zweiten Frage – Wie viel Prozent der Medien lügen Ihrer Meinung nach? – ergab sich aus dem Vortest, dass die Teilnehmer damit überfordert waren, selbstständig Angaben zu machen. Deshalb wurde eine vereinfachte Vorauswahl von Antworten gewählt (0 % die Medien lügen nicht, 10 % bis 40 %, die Hälfte, 60 % bis 90 %, 100 % alle Medien lügen). Diese Antwortvorgaben berücksichtigen nicht den Bereich 1 % bis 9 %, 41 % bis 49 %, 51 % bis 59 % und 91 % bis 99 %. Um die Antworten möglichst einfach zu gestalten, wurden diese Bereiche nicht berücksichtigt.
Reelle Rückschlüsse darauf, warum bestimmte Teilnehmergruppen auf eine Frage so geantwortet haben und andere gegenteilig, können nicht gezogen werden, da keine entsprechenden Daten erhoben wurden.
Schlussendlich ist zu diskutieren, inwieweit es vertretbar ist, in einer Umfrage Falschaussagen zu streuen und diese anschließend nicht aufzuklären. Der überwiegende Teil der Befragten war zum Zeitpunkt der Teilnahme volljährig (165 der 166 Befragten). Alle Teilnehmer hatten die Möglichkeit zur persönlichen Kontaktaufnahme. Keiner der Befragten bat um Aufklärung. Jedoch ist anzunehmen, dass ein kleiner Teil der Befragten eine der gelesenen Fake News weiterverbreitet hat. Da sie bewusst an einer Umfrage teilnahmen, in der sie entscheiden mussten, ob eine Aussage wahr oder unwahr ist, liegt die Verantwortung der Überprüfung ihrer persönlichen Annahme bei den Probanden selbst. Diese Verantwortung ist vergleichbar mit jeder anderen Rezeption von Medien. Von einer nachlaufenden Offenlegung, welche Nachricht richtig oder falsch ist, wurde abgesehen, da sich ein Teil der Befragten untereinander persönlich kennt. Damit hätte die Umfrage verfälscht werden können.
1 EINLEITUNG
1.1 Thematische Abgrenzung
1.2 Forschungsfrage
1.3 Methodik und Aufbau
2 GRUNDLAGEN ZU FAKE NEWS
2.1 Status quo
2.1 Definitionen
2.3 Theorie
2.3.1 Effekte
3 UMFELD
3.1 Rechtsgrundlagen
3.2 Unternehmen
3.2.1 Traditionelle Medien
3.2.2 Social Media
3.2.3 Alternative Medien
3.3 Journalismus
3.3.1 Russia Today
3.3.2 Breitbart
3.4 Politik
3.4.1 Parteien
3.5 Lobbyismus
3.5.1 Public Relations
3.6 Konsumenten
4 EMPIRISCHE UMFRAGE
4.1 Forschungsdesign
4.2 Datenerhebung und Datenaufbereitung
4.3 Datenauswertung
4.4 Berichtlegung
