
Visual Process Operating Systems
als neue Form organisationaler Steuerung
Wissenschaftliche Ausarbeitung | Konzeptionelle Modellentwicklung
Forschungsfrage: Wie kann ein graphbasiertes Visual Process Operating System die Transparenz, Entscheidungsqualität und wirtschaftliche Effizienz von Organisationen verbessern?
Abstract
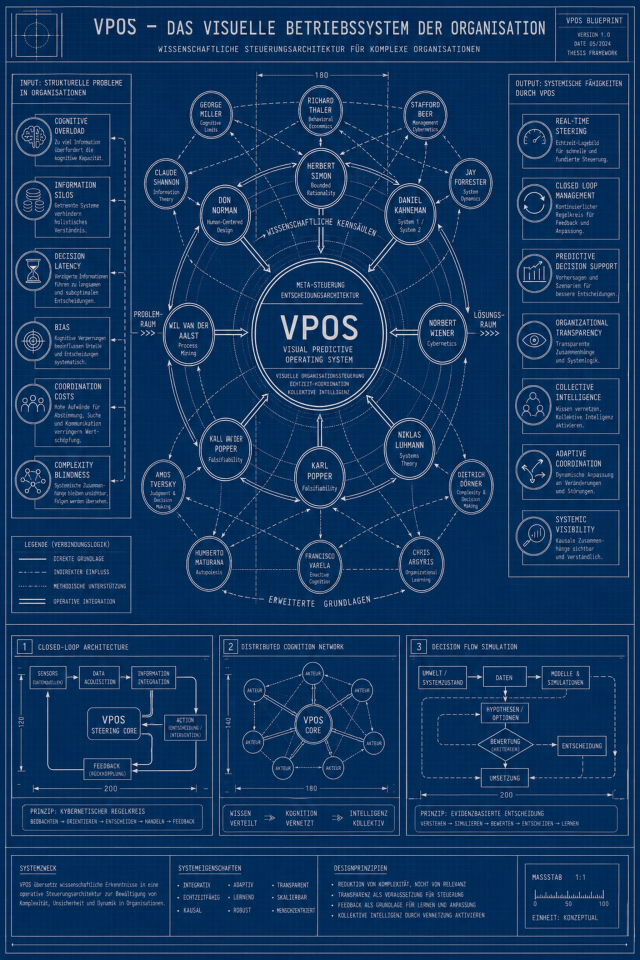
Die vorliegende Arbeit entwickelt das konzeptionelle Modell eines Visual Process Operating Systems (VPOS) als neuartige Architektur zur Steuerung von Organisationen als dynamische, datengetriebene Entscheidungsnetzwerke. Ausgangspunkt ist die strukturelle Unzulänglichkeit bestehender Informationssysteme, die Organisationen primär als Datenverwaltungssysteme behandeln und die Verbindung zwischen operativen Prozessen, Entscheidungsqualität und ökonomischer Wertschöpfung nur unzureichend abbilden.
Das VPOS-Modell formalisiert Organisationen als gerichtete, gewichtete Graphen G = (V, E), in denen Knoten ökonomisch bewertbare Prozessschritte und Kanten ihre Abhängigkeiten repräsentieren. Jeder Knoten erhält einen messbaren Wertbeitrag durch die Formel Vᵢ = Cᵢ · Qᵢ – Rᵢ, ergänzt um indirekte Netzwerkeffekte sowie einen integrierten Impact-Score für objektive Priorisierung. Eine spieltheoretische Erweiterung modelliert Rolleninteraktionen als strategische Spiele mit Nash-Gleichgewichten auf Knotenebene. Monte-Carlo-Simulationen ermöglichen probabilistische Szenarioanalysen statt statischer Punktprognosen.
Die Architektur besteht aus vier interdependenten Layern: Visual Layer (Visualisierung), Process Layer (Prozesslogik), Data Layer (ökonomisches Nervensystem) und Intelligence Layer (KI-gestützte Optimierung). Eine systematische Abgrenzung gegenüber marktführenden Systemen zeigt den spezifischen konzeptionellen Beitrag. Die Arbeit schließt mit einer empirischen Validierungsagenda und kritischer Reflexion der konzeptionellen Grenzen.
Schlüsselwörter: Visual Process Operating System, Graphentheorie, Entscheidungstheorie, Spieltheorie, Monte-Carlo-Simulation, Organisationssteuerung, Process Mining, KI-Integration, Wertschöpfungsarchitektur
1. Einleitung
1.1 Hintergrund und Relevanz der Arbeit
Die zunehmende Digitalisierung von Unternehmen hat in den vergangenen Jahrzehnten zu einer tiefgreifenden Transformation organisationaler Strukturen und Entscheidungsprozesse geführt. Informations- und Kommunikationstechnologien ermöglichen heute eine weitgehend vollständige Erfassung, Speicherung und Verarbeitung von Daten entlang der gesamten Wertschöpfungskette. Trotz dieser technologischen Fortschritte bleibt eine zentrale Herausforderung bestehen: die integrierte Steuerung von Organisationen als dynamische, datengetriebene Systeme (Davenport & Harris, 2007; Brynjolfsson & McAfee, 2014).
Bestehende Softwaresysteme – darunter Enterprise-Resource-Planning-Systeme wie SAP, Customer-Relationship-Management-Systeme wie Salesforce sowie Business-Process-Management-Plattformen wie Signavio – haben operationale Teilbereiche erheblich effizienter gestaltet. Dennoch weisen sie eine gemeinsame strukturelle Grenze auf: Sie modellieren Organisationen primär als Datenverwaltungssysteme und nicht als Netzwerke ökonomisch relevanter Entscheidungen. Prozesse, Entscheidungslogiken und wirtschaftliche Wirkungen verbleiben in getrennten Systemwelten (van der Aalst, 2016).
Diese Fragmentierung führt zu eingeschränkter Transparenz, verzögerten Entscheidungszyklen und unzureichender Sichtbarkeit von Kosten- und Margeneffekten auf Prozessebene. In einem zunehmend volatilen wirtschaftlichen Umfeld stellt dies ein strukturelles Wettbewerbsrisiko dar (Teece, 2007; Eisenhardt & Martin, 2000).
1.2 Problemstellung
Die zentrale Herausforderung moderner Organisationen besteht nicht primär in der Datenverfügbarkeit, sondern in der entscheidungsrelevanten Aufbereitung und kontextuellen Verknüpfung dieser Daten mit operativen Prozessen. Herbert A. Simon (1947) beschrieb Organisationen als Systeme begrenzter Rationalität, in denen Entscheidungen aufgrund unvollständiger Information suboptimal getroffen werden. Moderne Informationssysteme haben diese Grenze technisch verringert, aber konzeptionell nicht überwunden: Sie liefern mehr Daten, nicht notwendigerweise bessere Entscheidungsgrundlagen.
Konkret manifestiert sich das Problem in vier Dimensionen: erstens die Fragmentierung organisationaler Softwarelandschaften, zweitens die begrenzte Visualisierung von Kausalzusammenhängen, drittens steigende Koordinationskosten infolge undurchsichtiger Verantwortlichkeiten und viertens die mangelnde Verbindung zwischen Prozessausführung und ökonomischer Wirkungsmessung.
1.3 Zielsetzung und wissenschaftlicher Beitrag
Die vorliegende Arbeit verfolgt das Ziel, ein konzeptionelles Modell eines Visual Process Operating Systems (VPOS) zu entwickeln, das Organisationen als graphbasierte Entscheidungs- und Wertschöpfungssysteme beschreibt. Im Unterschied zu bestehenden Ansätzen integriert das VPOS vier Dimensionen in einem einheitlichen Rahmenwerk: Prozessmodellierung, ökonomische Knotenbewertung, spieltheoretische Rolleninteraktion und KI-gestützte Optimierung.
Der wissenschaftliche Beitrag der Arbeit liegt in der Formalisierung eines integrativen Konzepts, das bislang in der Literatur getrennt behandelte Forschungsstränge – Graphentheorie, Entscheidungstheorie, Spieltheorie und Prozessmanagement – in einem konsistenten Modell verbindet. Es handelt sich dabei ausdrücklich um eine konzeptionelle Modellentwicklung ohne empirische Validierung, die als Grundlage für zukünftige Forschungs- und Pilotprojekte dient.
1.4 Aufbau der Arbeit
Die Arbeit gliedert sich wie folgt: Kapitel 2 analysiert die Problemstellung durch eine systematische Betrachtung bestehender Softwarelandschaften. Kapitel 3 leitet daraus Forschungsziele ab. Kapitel 4 präzisiert die Forschungsfragen einschließlich falsifizierbarer Hypothesen. Kapitel 5 entwickelt den theoretischen Rahmen über sechs Theorieperspektiven, einschließlich der kognitiven Entscheidungstheorie nach Kahneman. Kapitel 6 entfaltet das VPOS-Konzept mit seinen vier Layern, dem Rollenmodell und den Arbeitsrimitiven. Kapitel 7 beschreibt eine mögliche Implementierungsstrategie. Kapitel 8 und 9 formalisieren das erweiterte mathematische Modell mit Wertpropagation, Monte-Carlo-Simulation, Centralitätsanalyse und Impact-Score. Kapitel 10 präsentiert das vollständige integrierte Modell. Kapitel 11 enthält den Systemvergleich und Kapitel 12 die kritische Würdigung mit empirischer Validierungsagenda.
2. Problemstellung
2.1 Fragmentierung organisationaler Softwarelandschaften
In den vergangenen Jahrzehnten haben Unternehmen erhebliche Investitionen in digitale Informationssysteme getätigt, um Geschäftsprozesse effizienter zu gestalten und datenbasierte Entscheidungen zu ermöglichen. In der Praxis hat sich dabei eine hochgradig fragmentierte Systemlandschaft etabliert, die aus einer Vielzahl spezialisierter Anwendungen besteht. Obwohl diese Systeme innerhalb ihrer jeweiligen Funktionsbereiche erhebliche Effizienzgewinne ermöglichen, führt ihre parallele Nutzung in Organisationen regelmäßig zu strukturellen Problemen: getrennte Datenräume, unterschiedliche Prozesslogiken sowie divergierende Steuerungsmodelle (Ross, Weill & Robertson, 2006).
Das Ergebnis ist eine organisationale Infrastruktur, die zwar datenorientiert ist, jedoch nur eingeschränkt entscheidungsorientiert. Informationen liegen in Form von Tabellen, Reports und isolierten Kennzahlen vor, ohne dass ihre systemische Wirkung auf die Gesamtwertschöpfung transparent wird. Das Silo-Paradox lautet: Jedes System optimiert rational nach seiner eigenen Logik – das Gesamtergebnis ist systemisch irrational.
2.2 Begrenzte Transparenz und Visualisierbarkeit von Kausalketten
Ein zentrales Problem besteht in der eingeschränkten Visualisierbarkeit komplexer organisatorischer Kausalzusammenhänge. In bestehenden Systemen werden Prozesse häufig abstrakt, textbasiert oder tabellarisch dargestellt. Dies erschwert sowohl das Verständnis für operative Mitarbeitende als auch für Entscheidungsträger auf strategischer Ebene.
Die Forschung zur kognitiven Entscheidungstheorie (Kahneman, 2011; Gigerenzer, 2008) zeigt, dass Menschen visuelle Repräsentationen effizienter verarbeiten als textbasierte Informationen und dass die Darstellungsform maßgeblich die Qualität von Entscheidungen beeinflusst. In bestehenden Softwaresystemen fehlt eine integrierte Visualisierungsebene, die Prozesse, Entscheidungslogiken und ökonomische Auswirkungen in einem kohärenten visuellen Modell zusammenführt.
2.3 Effizienzverluste und steigende Koordinationskosten
Die beschriebenen strukturellen Defizite führen zu messbaren Effizienzverlusten. Koordinationskosten entstehen als redundante Datenerfassung, unnötige Abstimmungsmeetings, Missverständnisse an Prozessschnittstellen und verzögerte Entscheidungszyklen. Coase (1937) identifizierte Koordinationskosten als zentralen Faktor für die Effizienz von Organisationen; Williamson (1975) erweiterte diese Perspektive um die Analyse von Transaktionskosten in institutionellen Kontexten.
Studien des McKinsey Global Institute zeigen, dass ein erheblicher Teil der Arbeitszeit von Wissensarbeitern – in der Größenordnung von rund 28 Prozent – auf das Suchen, Aufbereiten und Kommunizieren von Informationen entfällt, nicht auf die eigentliche Wertschöpfungsarbeit (McKinsey Global Institute, 2012). Diese Entscheidungslatenz – die Zeit zwischen dem Entstehen eines relevanten Signals und der entsprechenden Managemententscheidung – beträgt in traditionellen Organisationen häufig drei bis sechs Monate.
2.4 Entscheidungsqualität als zentraler Wettbewerbsfaktor
In modernen Organisationen gewinnt die Qualität von Entscheidungen zunehmend an wettbewerbsstrategischer Bedeutung. Teece, Pisano und Shuen (1997) beschreiben “dynamic capabilities” als Kernkompetenz von Unternehmen in turbulenten Umfeldern. Bestehende Informationssysteme unterstützen diesen Anspruch nur unzureichend: Sie fokussieren auf Dokumentation und Kontrolle, nicht auf Entscheidungsarchitekturen.
3. Forschungsziele und Zielsetzung der Arbeit
3.1 Übergeordnete Zielsetzung
Ziel dieser Arbeit ist die konzeptionelle und modelltheoretische Entwicklung eines Visual Process Operating Systems (VPOS) als Grundlage eines neuartigen Decision Operating Systems. Dabei soll untersucht werden, wie Organisationen durch graphbasierte Prozessarchitekturen, integrierte Datenstrukturen und algorithmische Entscheidungslogiken transparenter, effizienter und adaptiver gesteuert werden können.
3.2 Spezifische Forschungsziele
Forschungsziel 1: Systematische Analyse bestehender Organisations- und Informationssysteme hinsichtlich ihrer Architekturen, Entscheidungslogiken und strukturellen Grenzen in Bezug auf Transparenz, Adaptivität und Wertorientierung.
Forschungsziel 2: Entwicklung eines formalen graphbasierten Modells für ein Decision Operating System, das Organisationen als gerichtete, azyklische, gewichtete Graphen modelliert (DAG-Bedingung).
Forschungsziel 3: Ökonomische Bewertung des entwickelten Modells durch die Formalisierung von Wirkungsketten zwischen Transparenz, Entscheidungsqualität und Profitabilität sowie die Quantifizierung direkter und indirekter Knotenwertbeiträge.
Forschungsziel 4: Strategische Einordnung des Konzepts hinsichtlich Anwendungsfeldern, Skalierbarkeit und Wettbewerbspotenzial in verschiedenen Geschäftsmodellen und Organisationsgrößen.
3.3 Wissenschaftlicher Beitrag der Arbeit
Die Arbeit leistet einen Beitrag zur Diskussion um digitale Transformation, datengetriebene Steuerungssysteme und adaptive Organisationsformen, indem sie: (1) eine theoretische Weiterentwicklung von Organisationsmodellen hin zu graphbasierten Entscheidungsarchitekturen vornimmt, (2) Prozessmanagement, Datenökonomie und Spieltheorie konzeptionell integriert, (3) ein formalisiertes mathematisches Bewertungsmodell mit Wertpropagation, Centralitätsanalyse und Monte-Carlo-Simulation entwickelt und (4) die wirtschaftliche Wirkung und strategische Relevanz konzeptionell bewertet. Einschränkend ist festzuhalten, dass es sich ausdrücklich um konzeptionelle Modellentwicklung ohne empirische Validierung handelt.
4. Forschungsfragen
4.1 Hauptforschungsfrage
Im Zentrum dieser Arbeit steht folgende Hauptforschungsfrage:
Wie kann ein graphbasiertes Visual Process Operating System die Transparenz, Entscheidungsqualität und wirtschaftliche Effizienz von Organisationen konzeptionell verbessern, und welche formalen Modelle beschreiben diese Wirkungszusammenhänge?
4.2 Untergeordnete Forschungsfragen
Aus der Hauptforschungsfrage leiten sich folgende Teilfragen ab:
- F1: Welche strukturellen Defizite weisen bestehende Informationssysteme in Bezug auf Entscheidungsorientierung und ökonomische Transparenz auf?
- F2: Wie können organisationale Prozesse formal als graphbasierte Entscheidungs- und Wertschöpfungsnetzwerke modelliert werden?
- F3: Welche mathematischen Modelle eignen sich zur quantitativen Bewertung einzelner Prozessknoten im Hinblick auf ihren Wertbeitrag und ihre systemische Wirkung?
- F4: Wie können spieltheoretische Ansätze die Modellierung strategischer Interaktionen zwischen Rollen in Prozessknoten ergänzen?
- F5: In welchem Verhältnis steht das VPOS-Konzept zu bestehenden Ansätzen wie Process Mining, BPM und Workflow-Automatisierung?
4.3 Falsifizierbare Hypothesen
| Hypothese | Präzise Aussage | Wie falsifizierbar? |
| H1: Visualisierung erhöht Entscheidungsqualität | Entscheider mit VPOS-Graph treffen bei identischen Problemen messbar bessere Entscheidungen als solche mit klassischen Reports. | Kontrolliertes Laborexperiment: VPOS-Gruppe vs. Report-Gruppe, Messung Entscheidungsqualität und kognitive Belastung. |
| H2: Koordinationskosten sinken | Organisationen mit VPOS reduzieren messbare Koordinationskosten innerhalb von 12 Monaten nach Einführung. | Längsschnittdesign: Koordinationskosten (Meetings, Suchzeit) vor und nach VPOS-Einführung. |
| H3: Entscheidungslatenz sinkt | Mean Time to Detect (MTTD) von Prozessanomalien ist in VPOS-Organisationen signifikant kürzer als in Kontrollgruppen. | Quasi-Experiment mit MTTD als Kernmetrik, Vergleich VPOS vs. klassisches Reporting. |
4.4 Begründung und Abgrenzung
Die Forschungsfragen sind bewusst konzeptionell-theoretisch ausgerichtet, da die Arbeit keine empirische Validierung des VPOS-Modells anstrebt. Die Hypothesen H1–H3 sind falsifizierbar formuliert, können aber im Rahmen dieser Arbeit nicht überprüft werden – sie definieren den Rahmen zukünftiger Feldstudien und Laborexperimente (vgl. Kapitel 12.3).
5. Theoretischer Rahmen
5.1 Einordnung in bestehende Theorieperspektiven
Das VPOS-Konzept lässt sich an der Schnittstelle mehrerer etablierter Forschungsfelder verorten. Es integriert Perspektiven aus der Systemtheorie, Graphentheorie, Entscheidungstheorie, Spieltheorie, dem Prozessmanagement sowie dem Konzept digitaler Zwillinge. Jede Theorieperspektive adressiert eine spezifische Dimension des VPOS-Modells und liefert deren formale Fundierung.
5.2 Systemtheorie und Kybernetik
Ein grundlegender theoretischer Bezugspunkt ist die Allgemeine Systemtheorie nach Ludwig von Bertalanffy (1968). Organisationen werden hierbei als offene Systeme verstanden, die mit ihrer Umwelt interagieren und sich kontinuierlich anpassen. Das VPOS übernimmt diese Perspektive, indem es Organisationen als dynamische Netzwerke mit Interdependenzen und Anpassungsfähigkeit modelliert.
Eng damit verknüpft ist die Kybernetik nach Norbert Wiener (1948), die Regelkreise und Feedback-Mechanismen als zentrale Steuerungsprinzipien beschreibt. Das VPOS operiert als Closed-Loop-System: Jede ausgeführte Aktion erzeugt Daten, die in den Optimierungsprozess zurückfließen. Die Analogie ist präzise: Während ein klassischer Quartalsreport einem Open-Loop-System entspricht (Aktion ohne Echtzeit-Feedback), entspricht das VPOS einem Closed-Loop-System – vergleichbar mit einem Thermostat, der kontinuierlich misst, vergleicht und korrigiert. Entscheidungslatenz von Monaten wird auf Minuten bis Stunden reduziert.
5.3 Entscheidungstheorie, begrenzte Rationalität und kognitive Psychologie
Die konzeptionell bedeutsamste theoretische Grundlage bildet die Entscheidungstheorie Herbert A. Simons (1947, 1957). Simon zeigte, dass menschliche Entscheidungsfähigkeit durch begrenzte Informationsverarbeitungskapazität eingeschränkt ist (‘bounded rationality’) und dass Organisationen als Systeme zur Strukturierung von Entscheidungsprozessen verstanden werden können. Das menschliche Arbeitsgedächtnis kann maximal sieben Informationseinheiten gleichzeitig halten (Miller, 1956) – moderne Managemententscheidungen erfordern jedoch oft die simultane Verarbeitung von Hunderten von Variablen.
Besonders relevant ist Daniel Kahnemans Zwei-System-Modell des menschlichen Denkens (Kahneman, 2011): System 1 arbeitet automatisch, schnell und unbewusst; System 2 ist das bewusste, analytische, deliberative Denken – es ermüdet jedoch. Ein Manager, der morgens mit frischem System 2 beginnt und bis zum Abend Dutzende Entscheidungen getroffen hat, trifft abends Entscheidungen mit System 1-Heuristiken, obwohl er System 2 bräuchte. Das ist kein individuelles Versagen – es ist ein Designfehler des Systems.
Das VPOS-Designprinzip leitet sich direkt hieraus ab: System-2-Qualität mit System-1-Aufwand. Das System übernimmt die kognitiv teuren Vorverarbeitungsschritte – was beim Entscheider ankommt, ist kein Datensalat, sondern ein vorverarbeitetes, strukturiertes Lagebild. Kahneman und Tverskys (1979) Erkenntnisse zur Prospect Theory zeigen zusätzlich, dass menschliche Entscheidungen systematischen Verzerrungen unterliegen. Eine datenbasierte, visualisierte Entscheidungsarchitektur wie das VPOS kann diese Verzerrungen partiell reduzieren.
5.4 Graphentheorie und Netzwerkanalyse
Das methodische Fundament des VPOS liegt in der Graphentheorie, deren mathematische Grundlagen auf Euler (1736) zurückgehen. Organisationen werden als gerichtete, azyklische, gewichtete Graphen G = (V, E) modelliert. Die DAG-Bedingung (Directed Acyclic Graph) ist dabei keine Designentscheidung, sondern eine mathematische Notwendigkeit: Ein Graph mit Zyklen würde zu unendlicher Wertpropagation führen und Monte-Carlo-Simulationen mathematisch undefiniert machen.
In der Organisationsforschung haben graphbasierte Modelle breite Anwendung gefunden: Zentralitätsanalysen identifizieren kritische Knoten in Netzwerken, Community-Detection-Algorithmen erkennen organisationale Cluster, und dynamische Netzwerkanalysen simulieren Veränderungen über Zeit (Barabási, 2016; Newman, 2010). Das VPOS überträgt diese Methoden auf betriebliche Steuerungssysteme und ergänzt sie um eine ökonomische Bewertungsdimension.
5.5 Spieltheorie und strategische Interaktion
Die Spieltheorie (von Neumann & Morgenstern, 1944; Nash, 1950, 1951) liefert formale Werkzeuge zur Analyse strategischer Interaktionen unter der Annahme rationaler Akteure. Das VPOS integriert spieltheoretische Elemente in die Knotenbewertung: Jeder Prozessknoten wird nicht nur als technische Einheit, sondern als Interaktionspunkt zwischen Rollen mit möglicherweise divergierenden Zielen modelliert. Nash-Gleichgewichte beschreiben Zustände, in denen kein Akteur durch einseitige Strategieänderung besser gestellt wäre.
Darüber hinaus liefert das Mechanismusdesign (Hurwicz, 1960; Myerson, 1979) Grundlagen für die Gestaltung von Anreizsystemen im VPOS: Wie können Prozessregeln so gestaltet werden, dass individuell rationales Verhalten kollektiv optimale Ergebnisse produziert?
5.6 Prozessmanagement und Process Mining
Business Process Management (BPM) in der Tradition von Hammer und Champy (1993) sowie Davenport (1993) liefert konzeptionelle Grundlagen für die Prozessmodellierung im VPOS. Process Mining nach van der Aalst (2016) ergänzt dies durch die empirische Rekonstruktion realer Prozessabläufe aus Event-Logs. Das VPOS unterscheidet sich konzeptionell von Process-Mining-Ansätzen durch seinen prospektiv-steuernden Fokus: Während Process Mining diagnostisch rückblickt, zielt das VPOS auf proaktive Steuerung zukünftiger Entscheidungen.
5.7 Digitale Zwillinge und simulationsbasierte Organisationen
Das Konzept digitaler Zwillinge (Grieves, 2014; Tao et al., 2019) beschreibt die Echtzeitspiegelung physischer Systeme in digitalen Modellen. Das VPOS kann als ‘organisationaler digitaler Zwilling’ interpretiert werden: Die Organisation wird als aktuelles, datengespeistes Graphmodell repräsentiert, das Simulationen und Szenarioanalysen vor realen Entscheidungen ermöglicht.
Damit erweitert das VPOS klassische Business-Intelligence-Ansätze, die primär retrospektive Analysen liefern, um eine prospektive Steuerungsdimension.
5.8 Synthese der Theorieperspektiven
Die sechs beschriebenen Theorieperspektiven liefern jeweils einen spezifischen Beitrag zur Fundierung des VPOS-Modells: Die Systemtheorie begründet den Netzwerkcharakter von Organisationen, die Entscheidungstheorie und kognitive Psychologie legitimieren die Entscheidungszentriertheit und das Designprinzip ‘System-2-Qualität mit System-1-Aufwand’, die Graphentheorie liefert die formale Modellierungssprache, die Spieltheorie fundiert die Rolleninteraktionsmodellierung, das Prozessmanagement stellt die prozessuale Grundstruktur bereit und das Konzept digitaler Zwillinge rechtfertigt den Simulations- und Echtzeit-Anspruch.
6. Das Visual Process Operating System – Konzept und Architektur
6.1 Grundidee und konzeptionelle Positionierung
Das Visual Process Operating System (VPOS) postuliert einen Paradigmenwechsel in der organisationalen Steuerungslogik: von der datenverwaltenden Perspektive (‘Welche Daten existieren?’) zur entscheidungsorientierten Perspektive (‘Welche Entscheidungen erzeugen ökonomischen Wert?’). Die Kernannahme lautet: Unternehmen funktionieren in ihrer Substanz als Netzwerke von Entscheidungen entlang von Wertschöpfungsprozessen – nicht als Ansammlungen von Softwaremodulen oder Datenbankstrukturen.
6.2 Formale Systemdefinition
Das VPOS wird formal als gerichteter, azyklischer, gewichteter Graph definiert:
G = (V, E, A, R, F_V)
Die Bestandteile des Modells: V = {N₁, N₂, …, Nₙ} bezeichnet die Menge der Knoten als atomare oder aggregierte ökonomische Prozessschritte. E = {E_{ij}} bezeichnet die Menge der gerichteten Kanten. A bezeichnet den Attributvektor jedes Knotens (Zeitaufwand, Kosten, Risikoindikatoren, Entscheidungsstatus). R bezeichnet die Abbildung von Knoten auf Verantwortlichkeiten und Rollen. F_V bezeichnet die ökonomische Wertfunktion.
| Bedingung | Anforderung | Konsequenz bei Verletzung |
| 1. Strukturelle Integrität | Der Graph ist ein valider DAG ohne Zyklen, ohne isolierte Nodes. | Wertpropagation konvergiert nicht; Monte-Carlo-Simulation mathematisch undefiniert. |
| 2. Daten-Synchronität | Alle Node-Attribute werden in Echtzeit aus Quellsystemen synchronisiert. | Statische Daten führen zu veralteten Simulationen und falschen Alerts. |
| 3. Ökonomische Messbarkeit | Jeder Node hat quantifizierbare Kosten-, Zeit- und Risikoattribute. | Qualitative Nodes ohne Quantifizierung sind im Modell unzulässig. |
| 4. Rollenverantwortlichkeit | Jeder Entscheidungs-Node hat mindestens eine zugewiesene Rolle. | Ohne Entscheidungsverantwortung reduziert sich VPOS auf ein Flussdiagramm. |
| 5. Vollständige Attributierung | Kein Node darf mit unvollständigem Attributvektor betrieben werden. | Fehlende Attribute erzeugen blinde Flecken in Simulation und Optimierung. |
6.3 Die acht universellen Arbeitsprimitive
Eine zentrale Annahme des VPOS besteht darin, dass sich nahezu jede organisationale Tätigkeit auf acht grundlegende Handlungsprimitive reduzieren lässt. Diese Annahme lehnt sich an Konzepte der Aufgabenanalyse im Human Factors Engineering (Kirwan & Ainsworth, 1992) und an taxonomische Ansätze im Prozessmanagement an:
| Nr. | Primitiv | Layer-Zuordnung | Beispiel im VPOS |
| 1 | Input / Dokumentation – Aufnahme und Strukturierung von Daten | Process + Data | Erfassung von Angebotsdaten |
| 2 | Kommunikation – Informationsaustausch zwischen Rollen und Systemen | Visual | Benachrichtigungen, Status-Updates |
| 3 | Prüfung / Validierung – Abgleich gegen Regeln und Standards | Process | Compliance-Check, AGB-Scan |
| 4 | Entscheidung – Auswahl einer Handlung unter definierten Kriterien | Process + Intelligence | Freigabe, Ablehnung, Eskalation |
| 5 | Planung – Ressourcen- und Zeitallokation | Process + Intelligence | Kapazitätsplanung, Scheduling |
| 6 | Ausführung – Fachliche Durchführung der Aufgabe | Process | Bestellung ausführen, Dokument erstellen |
| 7 | Monitoring – Überwachung von Status und Leistung | Visual + Data | KPI-Tracking, SLA-Überwachung |
| 8 | Optimierung – Anpassung von Parametern zur Effizienzsteigerung | Intelligence | A/B-Tests, Parameter-Tuning |
Tabelle 1: Die acht universellen Arbeitsprimitive im VPOS mit Layer-Zuordnung und Beispielen
Diese Primitive bilden die atomaren Bausteine aller Workflows. Jeder Knoten im Graphen kann als Kombination dieser Arbeitsprimitive modelliert werden, wodurch eine standardisierte und vergleichbare Prozesslogik entsteht. Die Universalitätsannahme ist konzeptionell plausibel, bedarf jedoch empirischer Prüfung: Es ist denkbar, dass bestimmte Branchen oder kreative Tätigkeiten Primitive benötigen, die in diesem Rahmen nicht abgebildet sind (vgl. Kapitel 12).
6.4 Die vier-Layer-Architektur des VPOS
Die Gesamtarchitektur des VPOS besteht aus vier interdependenten Layern, die gemeinsam ein geschlossenes Regelkreissystem (Closed-Loop-System) bilden. Kein Layer ist für sich allein funktionsfähig.
6.4.1 Visual Layer – Kognitive Steuerungsschnittstelle
Der Visual Layer bildet die zentrale Mensch-Maschine-Schnittstelle des VPOS. Er stellt die gesamte Organisation als interaktives, visuelles Netzwerk dar: Prozessschritte als Knoten, Abhängigkeiten als Kanten, ökonomische Kennzahlen als kontextbezogene Annotationen direkt im Prozessfluss.
Die wissenschaftliche Grundlage für die Bedeutung von Visualisierung in Entscheidungsprozessen ist gut belegt. Larkin und Simon (1987) zeigten, dass diagrammatische Repräsentationen bestimmte Inferenzaufgaben erheblich vereinfachen. Tufte (1983) entwickelte Prinzipien der informationseffizienten Visualisierung. Im Unternehmenskontext belegen Studien, dass visuelle Dashboards im Vergleich zu tabellarischen Reports schnellere und präzisere Entscheidungen fördern (Few, 2009).
Der Visual Layer des VPOS unterscheidet sich von klassischen Business-Intelligence-Dashboards dadurch, dass KPIs nicht isoliert, sondern innerhalb der Prozessstruktur angezeigt werden. Die Marge eines Angebots erscheint nicht in einem separaten Report, sondern direkt am Prozessknoten „Finanzfreigabe“, wo sie entscheidungsrelevant ist. Diese Kontextualisierung reduziert kognitive Komplexität und erleichtert die Erkennung von Ursache-Wirkungs-Beziehungen.
6.4.2 Process Layer – Formalisierte Entscheidungsarchitektur
Der Process Layer formalisiert implizites Organisationswissen – das häufig nur in Meetings, E-Mails und Erfahrungswissen existiert – in eine explizite, strukturierte und steuerbare Prozessarchitektur. Er definiert Abläufe, Entscheidungslogiken, Rollen, Zuständigkeiten, Abhängigkeiten, Eskalationsmechanismen und Automatisierungsregeln.
Zentral ist die Entscheidungsarchitektur des Process Layers: Entscheidungen werden nicht als informelle Freigaben behandelt, sondern als definierte Knoten mit klaren Bedingungen, messbaren Auswirkungen und dokumentierten Verantwortlichkeiten. Beispielsweise wird die Bedingung „Freigabe nur wenn Marge > 18 %“ aus einer subjektiven Einschätzung zu einer systemischen Regel. Dies entspricht dem Konzept der „algorithmic decision-making“ (O’Neil, 2016; Diakopoulos, 2016), das die formale Spezifikation von Entscheidungsregeln zur Nachvollziehbarkeit und Konsistenz fordert.
Die ökonomische Verknüpfung unterscheidet den Process Layer von klassischen Workflow-Systemen: Jeder Prozessschritt kann mit Zeitaufwand, Ressourceneinsatz, Fixkostenanteil, variablen Kosten und Margeneffekt versehen werden, wodurch jede Handlung betriebswirtschaftlich messbar wird.
6.4.3 Data Layer – Ökonomisches Nervensystem
Der Data Layer ist das Datenfundament des VPOS. Er sammelt, strukturiert, validiert und verknüpft alle Daten aus operativen Prozessen in Echtzeit. Die Bezeichnung als „ökonomisches Nervensystem“ verweist auf seine Funktion als informationsverteilendes System, das sicherstellt, dass alle Steuerungsentscheidungen auf konsistenten, aktuellen Daten basieren.
Technisch integriert der Data Layer Daten aus ERP-, CRM-, Projektmanagement-, Marketing- und Kommunikationssystemen über standardisierte Schnittstellen (APIs, Webhooks). Er modelliert diese Daten nicht als isolierte Tabellen, sondern als graphbasierte Strukturen: Knoten repräsentieren Prozesse, Personen, Kunden und Produkte; Kanten repräsentieren Beziehungen, Abhängigkeiten und Verantwortlichkeiten.
Eine kritische Herausforderung für die praktische Implementierung ist die Datenqualität: Das Prinzip der „Single Source of Truth“ setzt bidirektionale Echtzeit-Anbindung an operative Drittsysteme voraus, die in der Praxis erhebliche Integration aufwands bedeutet. Dies ist eine der zentralen Implementierungshürden des Konzepts.
6.4.4 Intelligence Layer – Adaptive Optimierungsebene
Der Intelligence Layer nutzt die im Data Layer gespeicherten Informationen für Prognosen, Optimierungen und automatisierte Entscheidungsunterstützung. Er operiert im Closed-Loop-Prinzip: Echtzeitdaten fließen ein, Algorithmen erkennen Muster und Abweichungen, Optimierungsvorschläge werden an den Visual Layer zurückgegeben.
Technologisch stützt sich der Intelligence Layer auf Machine-Learning-Algorithmen (Predictive Analytics, Anomaly Detection), graphbasierte Algorithmen (Centrality, Shortest Path, Community Detection) sowie Optimierungsverfahren (lineare und nichtlineare Optimierung). Diese Werkzeuge sind in der Informatik und Operations Research gut etabliert (Cormen et al., 2009; Bishop, 2006).
Konzeptionell wichtig ist die Unterscheidung zwischen Entscheidungsunterstützung und Entscheidungsautomatisierung: Das VPOS respektiert menschliche Entscheidungsrechte. Automatisierte Entscheidungen erfolgen nur innerhalb vom Architekten definierter Vertrauensbereiche. Dieser „Human-in-the-Loop“-Ansatz (Amershi et al., 2014) ist sowohl ethisch geboten als auch praktisch notwendig, da hochkomplexe oder strategische Entscheidungen menschliches Urteil erfordern.
6.5 Goal Nodes und Incentive-Parameter
Ein Goal Node ist ein Meta-Knoten im VPOS-Graph, der einen strategischen Zielzustand explizit definiert. Er aggregiert die Outputs mehrerer Prozesspfade und bewertet sie in Bezug auf eine definierte Zielvariable (z.B. Deckungsbeitragsmaximierung, Durchlaufzeitminimierung, Cashflow-Stabilisierung). Goal Nodes lösen ein strukturelles Problem klassischer Unternehmenssteuerung: Strategie und operative Prozesse existieren in getrennten Systemen. Ein Goal Node macht diese Verbindung explizit und messbar.
Goal(Z) = Σ wᵢ · fᵢ(output(vᵢ)) für alle vᵢ ∈ G
Dabei bezeichnet Z die strategische Zielvariable, wᵢ das Gewicht des Knotens vᵢ für die Zielerreichung und fᵢ(…) die Beitragsfunktion. Im Visual Layer erscheinen Goal Nodes als übergeordnete Zielcluster: Bei Zoom-Out transformiert sich der operative Prozessgraph in eine Zielkarte. Bei Zoom-In wird sichtbar, welcher spezifische Knoten gerade den Marge-Goal-Node am stärksten unter Druck setzt.
6.6 Psychologische Sicherheit und Sichtbarkeit
VPOS macht Arbeit sichtbar – das ist sein Kernmechanismus. Diese Sichtbarkeit kann jedoch zwei gegensätzliche Wirkungen haben: als Kontrollinstrument (destruktiv) oder als Verstehsystem (konstruktiv). Amy Edmondson (1999) zeigte, dass psychologische Sicherheit – die gemeinsame Überzeugung, dass interpersonelles Risiko sicher eingegangen werden kann – der stärkste Prädiktor für Teamleistung ist.
| Dimension | VPOS als Kontrollinstrument (destruktiv) | VPOS als Verstehsystem (konstruktiv) |
| Anomalie-Alert | Wer hat den Node verzögert? | Welcher Prozessschritt ist systematisch zu komplex? |
| Leistungsdaten | Rangliste der Mitarbeiter nach Node-Durchsatz | Wo entsteht Engpass, der alle verlangsamt? |
| Entscheidungshistorie | Wer hat welche Entscheidung getroffen und warum war sie falsch? | Welche Entscheidungen wurden unter welchem Informationsstand getroffen? |
Gallup-Studien zeigen, dass das Mitarbeiter-Engagement weltweit bei 23 Prozent liegt; der stärkste Prädiktor für hohes Engagement ist das Gefühl, dass die eigene Arbeit sichtbar und bedeutsam ist. VPOS kann dieses Gefühl erzeugen – wenn Sichtbarkeit als Würde und nicht als Überwachung erfahren wird. Der Unterschied liegt in Governance und Führungskultur.
7. Implementierungsstrategie für bestehende Organisationen
7.1 Vorbemerkung und methodischer Rahmen
Die folgende Implementierungsstrategie beschreibt einen konzeptionellen Einführungspfad für das VPOS in bestehenden Organisationen. Sie basiert auf Erkenntnissen aus dem Change Management (Kotter, 1996), der IT-Implementierungsforschung (Markus, 1983) und agilen Einführungsansätzen. Es ist ausdrücklich darauf hinzuweisen, dass dieser Pfad ein konzeptionelles Ideal darstellt; reale Implementierungen werden kontextspezifische Anpassungen erfordern.
7.2 Phasenmodell der Implementierung
Phase 1 – Zieldefinition und Scope: Definition der strategischen Ziele (Effizienz, Transparenz, Profitabilität, Skalierbarkeit), Auswahl eines Pilotbereichs und Bestimmung der zu steuernden KPIs. Methodisch empfiehlt sich ein strategischer Workshop mit dem Führungsteam zur Risikominimierung und Orientierungssicherung.
Phase 2 – Prozessanalyse: Systematische Aufnahme aller relevanten Prozesse durch Workflow Mapping, Dokumentation von Zuständigkeiten und Identifikation von Engpässen. Diese Phase ist die empirische Grundlage der VPOS-Modellierung.
Phase 3 – Dateninventur und Strukturierung: Sammlung aller relevanten Datenquellen, Standardisierung der Datenformate und Definition von Kern-KPIs. Der Aufbau eines sauberen Data Layers ist Voraussetzung für alle nachgelagerten Funktionen.
Phase 4 – Prozessmodellierung im VPOS: Umsetzung analysierter Prozesse in den Process Layer, Definition von Rollen, Freigaben und Eskalationslogiken sowie Identifikation von Automatisierungspotenzialen.
Phase 5 – Aufbau des Visual Layers: Implementierung des Dashboards mit interaktiven Prozessgraphen, KPI-Visualisierungen und Simulationsfunktionen. Nutzer-Workshops sichern die Anpassung an reale Bedürfnisse.
Phase 6 – Intelligence Layer: Aufbau von ML-Modellen und Optimierungsalgorithmen, Automatisierung repetitiver Entscheidungen und Integration von Feedback-Schleifen.
Phase 7 bis 9 umfassen Pilotbetrieb und Iteration, Rollout und Skalierung sowie kontinuierliche Optimierung. Das Kernprinzip lautet: Erst verstehen und strukturieren, dann visualisieren und optimieren, anschließend lernen und skalieren.
8. Mathematisches Modell: Knotenwertberechnung
8.1 Grundidee und Motivation
Das mathematische Kernmodell des VPOS formalisiert die ökonomische Bewertung einzelner Prozessknoten sowie die systemische Analyse des gesamten Prozessgraphen. Der Organisationswert ist emergent – er entsteht aus der Interaktion der Teile, nicht aus den Teilen selbst:
V = f(G)
V bezeichnet den Gesamtwert der Organisation, f die Wertfunktion (abhängig von Topologie, Kantengewichten und Node-Attributen), G den vollständigen VPOS-Graph. Ein Netzwerk aus hundert gut verbundenen Nodes produziert mehr Wert als hundert isolierte Nodes mit demselben individuellen Potenzial.
8.2 Notation
| Symbol | Definition | Einheit / Wertebereich |
| Nᴵ | Knoten i im Prozessgraphen | diskrete Einheit |
| Cᴵ | Direkter ökonomischer Beitrag des Knotens (Umsatz, Kostenersparnis, Deckungsbeitrag) | €, normiert |
| Qᴵ | Qualitäts- / Erfolgswahrscheinlichkeit der Knotenausführung | [0, 1] |
| Rᴵ | Ressourcenaufwand (Personal, Zeit, Material, Fixkosten) | €, normiert |
| E_{ij} | Kantengewicht zwischen Knoten i und j (Abhängigkeitsstärke) | [0, 1] |
| Tᴵ | Prozessdauer des Knotens | Zeiteinheiten |
| Pᴵ | Ausfallwahrscheinlichkeit / Risiko der Nichtausführung | [0, 1] |
| Vᴵ | Gesamtwert des Knotens i | €, normiert |
Tabelle 2: Notation des VPOS-Knotenwertmodells
8.3 Direkter Knotenwert
Der direkte Wert eines Knotens ergibt sich als Differenz zwischen dem qualitätsbereinigten ökonomischen Beitrag und dem Ressourcenaufwand:
Vᵢᴰⁱʳ = Cᵢ · Qᵢ – Rᵢ
Beispiel: Ein Knoten mit Cᵢ = 100€, Qᵢ = 0,95 und Rᵢ = 20€ ergibt Vᵢᴰⁱʳ = 100 · 0,95 – 20 = 75€.
8.4 Indirekter Knotenwert durch Netzwerkeffekte
Da ein Knoten nachgelagerte Knoten beeinflusst, fließt sein Wert über die Kanten in das Gesamtsystem:
Vᵢᴵⁿᵈ = Σ (E_ij · V_j) für j ∈ Succ(i)
Die Wertpropagation beschreibt, wie sich Veränderungen in einem Knoten auf alle Nachfolger ausbreiten:
V(u) += w(v,u) · Δv(v) für alle u ∈ N(v)
Dabei bezeichnet N(v) die Menge aller direkten Nachfolger von v und Δv(v) die Wertveränderung in Node v. Diese Formel macht ein kritisches Prinzip mathematisch präzise: Eine lokale Verbesserung kann global schaden. Eine zehnprozentige Beschleunigung eines Produktions-Knotens ist nur dann gut, wenn alle nachgelagerten Knoten die erhöhte Outputrate verarbeiten können. Ohne Propagationsmodell ist jede Optimierung ein Experiment – mit Propagationsmodell ist sie eine Vorhersage (Modigliani & Miller, 1958; Metcalfe, 1980).
8.5 Gesamtwert und Erweiterungen
Der Gesamtwert eines Knotens kombiniert direkten und indirekten Wert:
Vᵢ = Vᵢᴰⁱʳ + Vᵢᴵⁿᵈ = Cᵢ · Qᵢ – Rᵢ + Σ (E_ij · V_j)
Zeitadjustierung: Der Wert pro Zeiteinheit als Vᵢᵀⁱᵐᵉ = Vᵢ / Tᵢ. Risikoadjustierung: Vᵢʳⁱˢᵏ = Vᵢ · (1 – Pᵢ). Ressourceneffizienz: Vᵢᵉᶠᶠ = Vᵢ / Σ R_ik.
8.6 Zentralitätsanalyse: Wer hat wirklich das Sagen im Graphen
| Metrik | Frage | Praktische Bedeutung |
| Betweenness Centrality C_B(v) | Durch wie viele kürzeste Pfade führt dieser Node? | Hoher Wert: Flaschenhals. Ausfall unterbricht viele Verbindungen. |
| Degree Centrality C_D(v) | Wie viele direkte Verbindungen hat dieser Node? | Hoher In-Degree bei Kapazitätsgrenze: klassischer Engpass. |
| Eigenvector Centrality C_E(v) | Wie gut vernetzt sind die Nachbarn dieses Nodes? | Hoher Wert: strategischer Einfluss, auch ohne direkten Flaschenhals. |
Google hat seine Suchmaschine auf einer Variante der Eigenvector Centrality aufgebaut: PageRank (Brin & Page, 1998). In VPOS funktioniert das Prinzip analog: Ein Knoten mit hoher Eigenvector Centrality ist mit anderen hochzentralen Knoten verbunden und hat dadurch strategischen Einfluss, auch ohne direkte Flaschenhals-Funktion. Zentralitätsanalyse macht die Machtstruktur des Prozessgraphen sichtbar – unabhängig von Organigrammen und Hierarchien (Freeman, 1977; Barabási & Albert, 1999).
8.7 Community Detection: Die wahre Organisationsstruktur
Community Detection identifiziert natürliche Cluster: Gruppen von Nodes, die untereinander stärker verbunden sind als mit dem Rest des Graphen. Der in VPOS eingesetzte Louvain-Algorithmus (Blondel et al., 2008) optimiert die Modularity Q:
Q = (1/2m) · Σ [A_ij – k_i·k_j/(2m)] · δ(c_i, c_j)
Dabei bezeichnet m die Gesamtanzahl Edges, A_ij die Adjazenzmatrix, k_i/k_j den Degree der Nodes und δ(c_i, c_j) = 1, wenn i und j in derselben Community sind. Je höher Q (Maximum = 1), desto klarer die Community-Struktur. Community Detection findet: Prozessmodule, die natürlich zusammengehören (auch über Abteilungsgrenzen hinweg), versteckte Silos als mathematischen Beweis und Nodes in der ‘falschen’ Community als Kandidaten für Umstrukturierung (Newman, 2006).
8.8 Kritischer Pfad und Impact-Score
Die Critical Path Method (Kelley & Walker, 1959) identifiziert den längsten Pfad im Graphen. Jede Verzögerung auf dem kritischen Pfad verzögert das Gesamtprojekt eins zu eins:
Float(v) = LS(v) – ES(v) [Float = 0: kritischer Pfad]
VPOS berechnet den kritischen Pfad in Echtzeit und aktualisiert ihn, wenn sich Node-Attribute oder Kantengewichte verändern. Der Impact-Score IS(v) integriert alle Dimensionen der Wichtigkeit:
IS(v) = α · C_B(v) + β · r(v) + γ · (1/Float(v)) + δ · ΔV(v)
Dabei bezeichnet C_B(v) die Betweenness Centrality, r(v) den Risikoindikator (Ausfallwahrscheinlichkeit × Impact), (1/Float(v)) den Kritischen-Pfad-Beitrag (unendlich wenn Float = 0) und ΔV(v) den marginalen Wertbeitrag bei Optimierung. Die Parameter α, β, γ, δ sind konfigurierbare Gewichtungsparameter (Saaty, 1980). Der Impact-Score ermöglicht eine objektive Priorisierungsmatrix:
| Hoher Impact-Score | Niedriger Impact-Score | |
| Niedrige Optimierungskosten | Q2: Sofort angehen. Höchste Return-on-Optimization. Priorität 1. | Q3: Opportunistisch optimieren, wenn Kapazität vorhanden. |
| Hohe Optimierungskosten | Q1: Transformations-Kandidaten. Sorgfältig priorisieren, Business Case kalkulieren. | Q4: Nicht optimieren. Ressourcenverschwendung. |
8.9 Monte-Carlo-Simulation
Das klassische Planungswerkzeug ist die Punktprognose: ‘Der Umsatz wird im nächsten Quartal 4,2 Millionen Euro betragen.’ Diese Zahl ist präzise – und fast immer falsch. Nicht weil der Analyst schlecht gearbeitet hat, sondern weil Zukunft grundsätzlich unsicher ist.
VPOS integriert die Monte-Carlo-Simulation (Ulam & von Neumann, 1946) in die Organisationssteuerung: Statt Punktprognosen liefert das System Wahrscheinlichkeitsverteilungen über das Gesamtergebnis des Graphen.
| Schritt | Was passiert | Beispiel |
| 1. Unsichere Variablen | Welche Node-Attribute sind nicht mit Sicherheit bekannt? | Durchlaufzeit t(v): historisch zwischen 3 und 7 Tagen |
| 2. Verteilungen festlegen | Welche Verteilung beschreibt die Unsicherheit? | Normalverteilung um 5 Tage, Standardabweichung 1 Tag |
| 3. N Szenarien simulieren | Werte ziehen, durch Graphen propagieren | N = 10.000 bis 100.000 Szenarien in Sekunden |
| 4. Ergebnisverteilung | Mittelwert, Standardabweichung, Perzentile | V_total: 90%-Intervall 3,8 bis 4,7 Mio. Euro |
| 5. Visualisieren | Wahrscheinlichkeitsverteilung im Visual Layer | “In 5% der Szenarien ist der Wert negativ.” |
Die strategische Implikation: Vor jeder externen Zusage berechnet das System ein Konfidenzintervall. Liegt die Wahrscheinlichkeit der Einlösbarkeit über dem Schwellwert, wird die Zusage gegeben. Monte-Carlo verwandelt Ungewissheit in Risikomanagement – nicht in Glücksspiel.
8.10 Interpretation und Implikationen
Das mathematische Modell erlaubt die farbliche Visualisierung im Visual Layer als Heatmap: Knoten mit hohem Vᵢ erscheinen grün, kritische Knoten mit niedrigem Vᵢ oder hohem Risiko erscheinen rot. Methodische Einschränkung:Die praktische Operationalisierung der Knotenwertformel setzt die verlässliche Messbarkeit von Cᵢ und Rᵢ für jeden einzelnen Prozessknoten voraus. Dies ist in der Praxis eine erhebliche Herausforderung, da viele Prozessschritte keine direkt zurechenbaren Kosten oder Erlöse aufweisen.
9. Spieltheoretische Erweiterung des VPOS-Modells
9.1 Motivation und konzeptionelle Grundlage
Organisationale Prozesse sind selten isolierte technische Abläufe. An jedem Entscheidungsknoten interagieren Akteure – Rollen wie CFO, Einkauf, Qualitätsmanager oder KI-Agenten – mit möglicherweise divergierenden Interessen, Informationen und Anreizstrukturen. Die Spieltheorie (von Neumann & Morgenstern, 1944; Nash, 1950) liefert formale Werkzeuge zur Analyse dieser strategischen Interaktionen.
9.2 Formale Modellierung
Sei Nᵢ ein Prozessknoten mit n beteiligten Rollen R₁, R₂, …, Rₙ. Die Nutzenfunktion von Rolle R_j ist definiert als:
U_j(s₁, s₂, …, sₙ) = α · Vᵢᴰⁱʳ – β · R_j + γ · Q_j
Ein Nash-Gleichgewicht S* = (s₁*, s₂*, …, sₙ*) ist ein Strategieprofil, bei dem keine Rolle durch einseitige Abweichung einen höheren Nutzen erzielen kann. Im VPOS-Kontext beschreibt das Nash-Gleichgewicht einen stabilen Zustand kollektiver Entscheidungsfindung.
9.3 Anwendungsfälle im VPOS
Konfliktanalyse: Marketing möchte ein Produkt früher freigeben (höhere Wachstumsrate), die Qualitätskontrolle präferiert längere Prüfzeiten (höhere Qualität). Das spieltheoretische Modell identifiziert ein Nash-Gleichgewicht als Kompromissstrategie.
Ressourcenallokation: Mehrere Prozessknoten konkurrieren um begrenzte Ressourcen. Kooperative Spielstrategien (Shapley-Wert, Nucleolus) können faire und effiziente Ressourcenverteilungen berechnen (Osborne & Rubinstein, 1994).
Incentive Design: Der Intelligence Layer kann spieltheoretisch fundierte Anreizsysteme implementieren, die individuell rationales Verhalten an organisationale Ziele ankoppeln.
9.4 Grenzen der spieltheoretischen Modellierung
Die spieltheoretische Erweiterung setzt die Modellierbarkeit von Präferenzen und Nutzenfunktionen voraus – eine Annahme, die in der Praxis schwierig zu operationalisieren ist. Reale Rollenverhalten sind häufig durch begrenzte Rationalität, Informationsasymmetrien und institutionelle Faktoren geprägt. Die Modellierung gilt daher als konzeptionelle Näherung, die einer empirischen Kalibrierung bedarf.
10. Vollständiges integriertes Modell
10.1 Gesamtstruktur des VPOS
Das vollständige VPOS-Modell verbindet alle bisher entwickelten Elemente in einer konsistenten formalen Struktur:
G = (N, E, V, R, Q, S, U)
N ist die Menge der Prozessknoten; E die Menge der gewichteten Abhängigkeitskanten; V die Menge der Knotenwertfunktionen; R die Menge der Rollenabbildungen; Q die Qualitätsparameter; S die Strategiemengen der Rollen; U die Nutzenfunktionen. Die Integration dieser Komponenten ermöglicht sowohl die statische Modellierung der Organisationsstruktur als auch die dynamische Simulation von Entscheidungsfolgen.
10.2 KI-Optimierung im vollständigen Modell
Der Intelligence Layer maximiert den Gesamtwert des Prozessgraphen durch algorithmische Optimierung:
S*_AI = argmax_S Σ Vᵢᵃᵈʲ(S) für alle i ∈ N
Diese Optimierung berücksichtigt Ressourcenbeschränkungen, Qualitätsparameter und strategisches Rollenverhalten. Sie arbeitet über kontinuierliche Feedbackschleifen: ausgeführte Entscheidungen erzeugen Daten, die Modellparameter aktualisieren, die wiederum verbesserte Empfehlungen generieren.
10.3 Rollenmodell im vollständigen System
| Rolle | Kernaufgabe | Entscheidungshoheit | Typische Position |
| Operator | Führt Ausführungs- und Monitoring-Primitive durch | Keine, außerhalb definierter Parameter | Sachbearbeiter, Produktionsmitarbeiter |
| Reviewer | Prüft Outputs gegen Qualitätskriterien | Nur über Qualitätsstandards | Qualitätsprüfer, Compliance-Beauftragter |
| Entscheider | Wählt zwischen Optionen mit Downstream-Konsequenzen | Vollständig, mit vollständiger Accountability | Manager, Führungskräfte |
| Analyst | Bereitet Daten für Entscheider auf | Keine Entscheidungsverantwortung | Controller, Business Analyst |
| Architekt | Definiert und verändert die Graph-Topologie | Root-Zugriff auf VPOS-Struktur | VPOS-Implementierer, IT-Architekt |
| Stratege | Trifft Richtungsentscheidungen über das Gesamtsystem | Strategische KPIs, Trade-offs, Scope | Geschäftsführung, Vorstand |
11. Systemvergleich: VPOS und bestehende Lösungen
11.1 Analysierte Systeme und Vergleichsmethodik
Der folgende Vergleich analysiert vier marktführende Systeme – Celonis, SAP Signavio, Pega und IBM Process Mining – anhand einheitlicher Vergleichsdimensionen. Die Analyse folgt einem konzeptionellen Vergleichsrahmen und dient der wissenschaftlichen Verortung des VPOS-Konzepts.
| Kriterium | Celonis | SAP Signavio | Pega | IBM Proc. Mining | VPOS (ARCADIO) |
| Primäre Funktion | Process Mining / Diagnose | BPM-Modellierung | Workflow-Automation | Process Mining / BI | Entscheidungs-Architektur |
| Zeitliche Orientierung | Retrospektiv | Statisch-dokumentierend | Echtzeit-Ausführung | Retrospektiv | Proaktiv-steuernd |
| Graphbasierte Modellierung | Partiell (Event-Logs) | BPMN 2.0-Notation | Nicht vorhanden | Partiell (Event-Logs) | Native Graph-Architektur (DAG) |
| Ökon. Node-Bewertung | Nicht vorhanden | Nicht vorhanden | Eingeschränkt | Nicht vorhanden | Kernfunktion (Vᵢ-Formel) |
| Spieltheoret. Modellierung | Nicht vorhanden | Nicht vorhanden | Nicht vorhanden | Nicht vorhanden | Nash-Gleichgewicht auf Node-Ebene |
| Monte-Carlo-Simulation | Nicht vorhanden | Nicht vorhanden | Nicht vorhanden | Eingeschränkt | Kernfunktion (probabilistisch) |
| Impact-Score / Priorisierung | Eingeschränkt | Nicht vorhanden | Nicht vorhanden | Eingeschränkt | IS(v) = α·C_B + β·r + γ·Float⁻¹ + δ·ΔV |
| KI-Integration | ML-Erweiterungen (EMS) | Begrenzt | Regelbasiert / Adaptiv | Watson-ML-Integration | Intelligence Layer (strukturell) |
| Empirischer Reifegrad | Marktreif, validiert | Marktreif, validiert | Marktreif, validiert | Marktreif, validiert | Konzeptionell (kein Pilotbetrieb) |
11.2 Konzeptionelle Differenzierung
Die wissenschaftlich verteidigbare Differenzierung des VPOS ergibt sich in drei Dimensionen: (1) Entscheidungszentriertheit statt Prozessorientierung, (2) mathematische Knotenwertberechnung mit Wertpropagation, Centralitätsanalyse und Monte-Carlo-Simulation, (3) spieltheoretische Rollenmodellierung mit Nash-Gleichgewichten auf Knotenebene. Die Abgrenzung gegenüber Celonis EMS ist gradueller als konzeptionell beschrieben – Celonis entwickelt sich aktiv in Richtung Echtzeit-Steuerung. Der spieltheoretische Beitrag bleibt das genuinste Alleinstellungsmerkmal.
11.3 Positionierungsempfehlung
Das Visual Process Operating System ist das erste konzeptionelle Rahmenwerk, das Prozessmanagement, ökonomische Entscheidungsbewertung auf Knotenebene, probabilistische Simulation und spieltheoretische Rollenmodellierung in einem einheitlichen graphbasierten Modell formalisiert.
12. Kritische Reflexion und Limitationen
12.1 Stärken des Konzepts
Das VPOS-Konzept überzeugt durch seine konzeptionelle Kohärenz: Die Integration von Systemtheorie, kognitiver Psychologie (Kahneman), Graphentheorie, Entscheidungstheorie und Spieltheorie in einem geschlossenen Modell ist theoretisch solide hergeleitet. Das erweiterte mathematische Modell – mit Wertpropagation, Centralitätsanalyse, Community Detection, Monte-Carlo-Simulation und Impact-Score – bietet einen operationalisierbaren Rahmen für die ökonomische Steuerung von Organisationen.
12.2 Zentrale Limitationen
Limitation 1 – Fehlende empirische Validierung: Das VPOS ist ein konzeptionelles Modell ohne Pilotbetrieb. Die postulierten Wirkungsketten (Visualisierung → Transparenz → bessere Entscheidungen → höhere Profitabilität) sind plausibel, aber empirisch nicht belegt.
Limitation 2 – Operationalisierungsprobleme: Die Knotenwertformel setzt zurechenbare Cᵢ- und Rᵢ-Werte für jeden Prozessschritt voraus. In der Praxis können viele Knoten – etwa strategische Entscheidungen oder kreative Tätigkeiten – nicht direkt mit Kostenwerten verankert werden.
Limitation 3 – Implementierungskomplexität: Die Single-Source-of-Truth-Anforderung des Data Layers setzt tiefe, bidirektionale Integration mit bestehenden ERP- und CRM-Systemen voraus. Diese Integration ist technisch und organisatorisch aufwändig (Markus, 1983).
Limitation 4 – Gradueller Unterschied zu Wettbewerbern: Die Differenzierung gegenüber Celonis EMS ist gradueller als konzeptionell beschrieben. Celonis entwickelt sich aktiv in Richtung Echtzeit-Steuerung.
Limitation 5 – Universalität der Arbeitsprimitive: Die Annahme, dass alle organisationalen Tätigkeiten auf acht Primitive reduzierbar sind, ist konzeptionell attraktiv, aber empirisch ungeprüft.
Limitation 6 – Modellierungskomplexität: Die vollständige Modellierung einer mittelständischen Organisation mit 200 Prozessschritten als valider VPOS-Graph erfordert erheblichen initialen Aufwand. Wenn dieser Aufwand unterschätzt wird, scheitert die Implementierung nicht an der Technologie, sondern am Change Management.
12.3 Empirische Validierungsagenda
| Hypothese | Forschungsdesign | Mindest-Datenbedarf | Zeitrahmen |
| H1: Visualisierung erhöht Entscheidungsqualität | Kontrolliertes Laborexperiment: zwei Gruppen lösen identische Entscheidungsprobleme, eine mit VPOS-Graph, eine mit klassischem Report. | 60 Probanden, 3 Entscheidungsszenarien, Pre/Post-Messung kognitive Belastung | 6–12 Monate |
| H2: Koordinationskosten sinken | Längsschnittdesign: Pre/Post-Messung der Koordinationszeiten (Meetings, Suche, E-Mail) in 3 Organisationen mit VPOS vs. Kontrollgruppe. | 3 Unternehmen, 50+ Mitarbeiter, 6 Monate Basisdaten | 12–18 Monate |
| H3: Entscheidungslatenz sinkt | Quasi-Experiment: Mean Time to Detect (MTTD) von Anomalien vor und nach VPOS-Einführung. | MTTD-Logs aus mindestens 100 Anomalie-Events, Kontrollgruppe ohne VPOS | 12–24 Monate |
Zusätzlich sind folgende Forschungsfelder prioritär: (1) Simulation des VPOS-Modells mit synthetischen Organisationsdaten, (2) spieltheoretische Laborexperimente zur Validierung des Rolleninteraktionsmodells, (3) empirische Prüfung der Universalitätsannahme der acht Arbeitsprimitive.
13. Literaturverzeichnis
Amershi, S., Cakmak, M., Knox, W. B., & Kulesza, T. (2014). Power to the People: The Role of Humans in Interactive Machine Learning. AI Magazine, 35(4), 105–120.
Barabási, A.-L. (2016). Network Science. Cambridge University Press.
Barabási, A.-L. & Albert, R. (1999). Emergence of Scaling in Random Networks. Science, 286(5439), 509–512.
Bertalanffy, L. von (1968). General System Theory: Foundations, Development, Applications. George Braziller.
Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
Blondel, V.D., Guillaume, J.-L., Lambiotte, R. & Lefebvre, E. (2008). Fast unfolding of communities in large networks. Journal of Statistical Mechanics, 2008(10), P10008.
Bonacich, P. (1987). Power and Centrality: A Family of Measures. American Journal of Sociology, 92(5), 1170–1182.
Brin, S. & Page, L. (1998). The Anatomy of a Large-Scale Hypertextual Web Search Engine. Computer Networks, 30(1–7), 107–117.
Brynjolfsson, E., & McAfee, A. (2014). The Second Machine Age. W. W. Norton & Company.
Brynjolfsson, E., & Saunders, A. (2010). Wired for Innovation. MIT Press.
Coase, R. H. (1937). The Nature of the Firm. Economica, 4(16), 386–405.
Cormen, T. H., Leiserson, C. E., Rivest, R. L., & Stein, C. (2009). Introduction to Algorithms (3. Aufl.). MIT Press.
Davenport, T. H. (1993). Process Innovation: Reengineering Work Through Information Technology. Harvard Business School Press.
Davenport, T. H., & Harris, J. G. (2007). Competing on Analytics. Harvard Business School Press.
Diakopoulos, N. (2016). Accountability in Algorithmic Decision Making. Communications of the ACM, 59(2), 56–62.
Diestel, R. (2017). Graph Theory (5. Aufl.). Springer.
Edmondson, A. C. (1999). Psychological Safety and Learning Behavior in Work Teams. Administrative Science Quarterly, 44(2), 350–383.
Eisenhardt, K. M., & Martin, J. A. (2000). Dynamic Capabilities: What Are They? Strategic Management Journal, 21(10–11), 1105–1121.
Euler, L. (1736). Solutio problematis ad geometriam situs pertinentis. Commentarii Academiae Scientiarum Imperialis Petropolitanae, 8, 128–140.
Few, S. (2009). Now You See It: Simple Visualization Techniques for Quantitative Analysis. Analytics Press.
Freeman, L. C. (1977). A Set of Measures of Centrality Based on Betweenness. Sociometry, 40(1), 35–41.
Gigerenzer, G. (2008). Rationality for Mortals. Oxford University Press.
Goldratt, E. M. (1997). Critical Chain. North River Press.
Grieves, M. (2014). Digital Twin: Manufacturing Excellence through Virtual Factory Replication. White Paper.
Hammer, M., & Champy, J. (1993). Reengineering the Corporation. Harper Business.
Hurwicz, L. (1960). Optimality and Informational Efficiency in Resource Allocation Processes. In K. Arrow, S. Karlin & P. Suppes (Hrsg.), Mathematical Methods in the Social Sciences. Stanford University Press.
Kahneman, D. (2011). Thinking, Fast and Slow. Farrar, Straus and Giroux.
Kahneman, D., & Tversky, A. (1979). Prospect Theory: An Analysis of Decision under Risk. Econometrica, 47(2), 263–291.
Keen, P. G. W., & Scott Morton, M. S. (1978). Decision Support Systems: An Organizational Perspective. Addison-Wesley.
Kelley, J. E. & Walker, M. R. (1959). Critical-Path Planning and Scheduling. Proceedings of the Eastern Joint Computer Conference, 160–173.
Kirwan, B., & Ainsworth, L. K. (Hrsg.). (1992). A Guide to Task Analysis. Taylor & Francis.
Kotter, J. P. (1996). Leading Change. Harvard Business School Press.
Larkin, J. H., & Simon, H. A. (1987). Why a Diagram is (Sometimes) Worth Ten Thousand Words. Cognitive Science, 11(1), 65–100.
Luhmann, N. (1984). Soziale Systeme: Grundriss einer allgemeinen Theorie. Suhrkamp.
Markus, M. L. (1983). Power, Politics, and MIS Implementation. Communications of the ACM, 26(6), 430–444.
McKinsey Global Institute (2012). The Social Economy: Unlocking Value and Productivity Through Social Technologies. McKinsey & Company.
Metcalfe, R. (1980). Metcalfe’s Law: Der Wert eines Netzwerks wächst proportional zum Quadrat seiner Nutzer.
Miller, G. A. (1956). The Magical Number Seven, Plus or Minus Two. Psychological Review, 63(2), 81–97.
Modigliani, F. & Miller, M. H. (1958). The Cost of Capital, Corporation Finance and the Theory of Investment. American Economic Review, 48(3), 261–297.
Myerson, R. B. (1979). Incentive Compatibility and the Bargaining Problem. Econometrica, 47(1), 61–73.
Nash, J. F. (1950). Equilibrium Points in n-Person Games. Proceedings of the National Academy of Sciences, 36(1), 48–49.
Nash, J. F. (1951). Non-Cooperative Games. Annals of Mathematics, 54(2), 286–295.
Newman, M. E. J. (2006). Modularity and community structure in networks. Proceedings of the National Academy of Sciences, 103(23), 8577–8582.
Newman, M. E. J. (2010). Networks: An Introduction. Oxford University Press.
O’Neil, C. (2016). Weapons of Math Destruction. Crown Publishers.
Osborne, M. J., & Rubinstein, A. (1994). A Course in Game Theory. MIT Press.
Popper, K. R. (1934/1959). The Logic of Scientific Discovery. Hutchinson.
Porter, M. E. (1985). Competitive Advantage: Creating and Sustaining Superior Performance. Free Press.
Power, D. J. (2002). Decision Support Systems: Concepts and Resources for Managers. Quorum Books.
Ross, J. W., Weill, P., & Robertson, D. C. (2006). Enterprise Architecture as Strategy. Harvard Business School Press.
Saaty, T. L. (1980). The Analytic Hierarchy Process. McGraw-Hill.
Simon, H. A. (1947). Administrative Behavior. Macmillan.
Simon, H. A. (1955). A Behavioral Model of Rational Choice. Quarterly Journal of Economics, 69(1), 99–118.
Simon, H. A. (1957). Models of Man. Wiley.
Simon, H. A. (1962). The Architecture of Complexity. Proceedings of the American Philosophical Society, 106(6), 467–482.
Slack, N., Chambers, S. & Johnston, R. (2010). Operations Management (6. Aufl.). Pearson.
Tao, F., Zhang, H., Liu, A., & Nee, A. Y. C. (2019). Digital Twin in Industry: State-of-the-Art. IEEE Transactions on Industrial Informatics, 15(4), 2405–2415.
Teece, D. J. (2007). Explicating Dynamic Capabilities. Strategic Management Journal, 28(13), 1319–1350.
Teece, D. J., Pisano, G., & Shuen, A. (1997). Dynamic Capabilities and Strategic Management. Strategic Management Journal, 18(7), 509–533.
Tufte, E. R. (1983). The Visual Display of Quantitative Information. Graphics Press.
van der Aalst, W. M. P. (2016). Process Mining: Data Science in Action (2. Aufl.). Springer.
von Neumann, J., & Morgenstern, O. (1944). Theory of Games and Economic Behavior. Princeton University Press.
Wiener, N. (1948). Cybernetics: Or Control and Communication in the Animal and the Machine. MIT Press.
Williamson, O. E. (1975). Markets and Hierarchies. Free Press.
